


Did you know you can run powerful AI models right on your computer? It’s true! Today, I will show you how easy it is to get started with Llama 3.2 and OpenWebUI.
Watch on YouTube: Run AI On YOUR Computer
Running Llama 3.2 Locally: A Comprehensive Guide
Introduction to Llama 3.2
Llama 3.2 is the latest iteration of Meta’s open-source language model, offering enhanced capabilities for text and image processing. It is designed to run efficiently on local devices, making it ideal for applications that require privacy and low latency. The model comes in various sizes, including 1B, 3B, and 11B parameters. In this tutorial, I’m going to use the 1B model, but you can download any you like.

Introduction to Llama 3.2
Before setting up Llama 3.2 locally, ensure you have the following:
A computer with Windows, macOS, or Linux. I’m going to use Linux (Ubuntu).
Basic knowledge of using the terminal or command prompt.
Step-by-Step Installation Guide
Step 1: Install Docker
Docker is a tool that allows developers to package applications and their dependencies into a standardized unit called a container, which can run consistently across different computing environments. Unlike virtual machines, containers are lightweight and share the host system’s operating system, making them more efficient and faster to start.
Docker
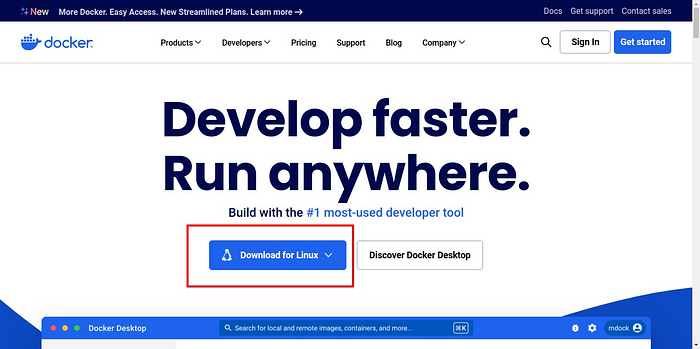
You can download the Docker Desktop application from the Docker website https://www.docker.com/ or via the terminal. Docker is available for Mac, Windows, and Linux.
How to Install Docker on Ubuntu
Download the package https://desktop.docker.com/linux/main/amd64/docker-desktop-amd64.deb
Then use these commands:
sudo apt-get update
sudo apt-get install [path to the docker package].deb
More details: https://docs.docker.com/desktop/install/linux/ubuntu/
Step 2: Install Ollama
Ollama is essential for running large language models like Llama 3.2 locally.
Install Ollama
Follow these steps to install it:
Visit the official Ollama website and download the installer for your operating system.
Run the installer and follow the on-screen instructions to complete the installation.
Verify the installation by opening a terminal (or command prompt) and typing
ollama. You should see a list of commands if installed correctly.
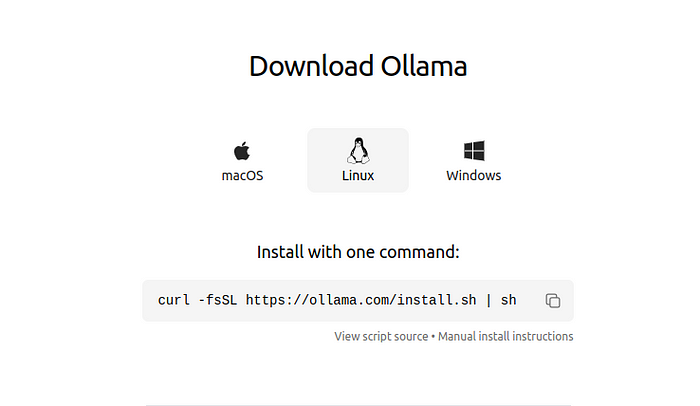
I’m going to use the terminal and this command:
curl -fsSL https://ollama.com/install.sh | sh
Step 3: Download a New Llama 3.2 model from Ollama website
Once Ollama is set up, you can download Llama 3.2 models. All the available models you can find here https://ollama.com/library
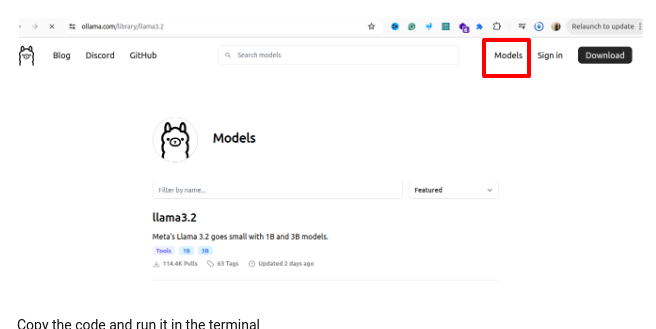
Download a New Llama 3.2
Since I want to use 1B parameters model I’ll be using this command:
ollama run llama3.2:1b
Step 4: Install OpenWebUI with Default Configuration
OpenWebUI is a self-hosted, extensible web interface designed to interact entirely offline with large language models (LLMs). It offers a user-friendly experience similar to ChatGPT, supports integration with various LLMs, such as those compatible with OpenAI and Ollama, and provides features like markdown support, model management, and multi-user access.
Go to https://docs.openwebui.com/getting-started/ and find the section Quick Start with Docker. Copy the code and then run it in the terminal.
I’m going to run this code:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
We will run a Docker command. It is used to run a containerized version of the OpenWebUI application.
Once the installation is finished, open your browser and go to http://0.0.0.0:3000/. If everything is okay, you will see the website. Create an account, and then you will see the welcome screen, which is similar to ChatGPT.
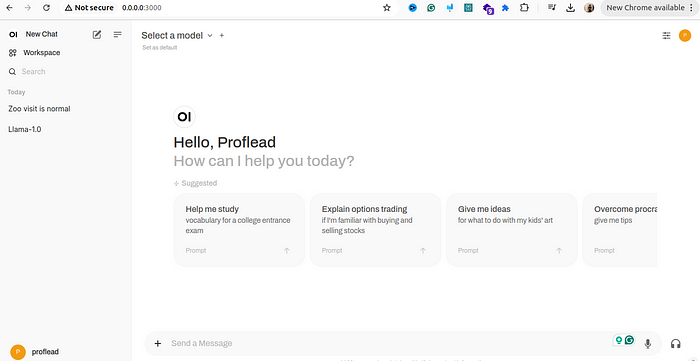
Llama 3.2 in Browser
Troubleshooting Common Issue
WebUI models not being pulled/applied
Some of you could face an issue when the models are not available in the drop-down. To fix it, follow these instructions:
- Go to the settings at the bottom left corner.
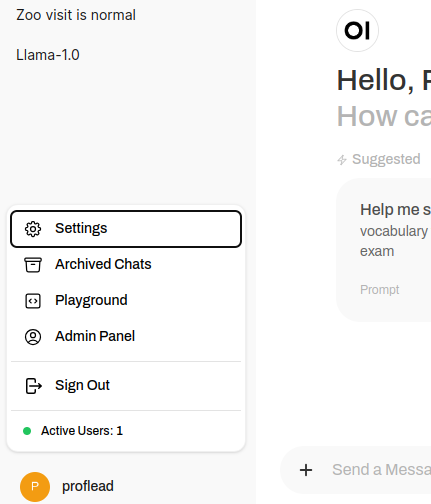
Settings
2. Click on “Admin Settings”.
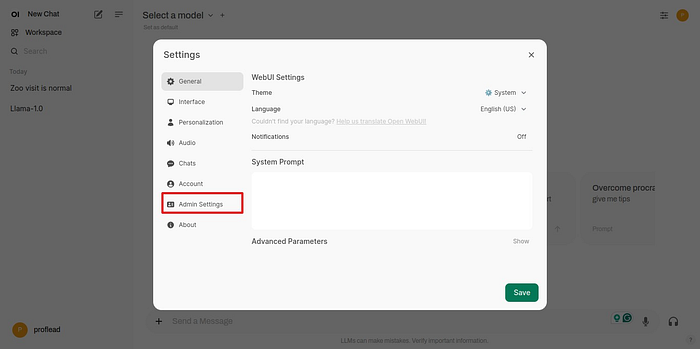
Admin Settings
3. Click on “Models.”
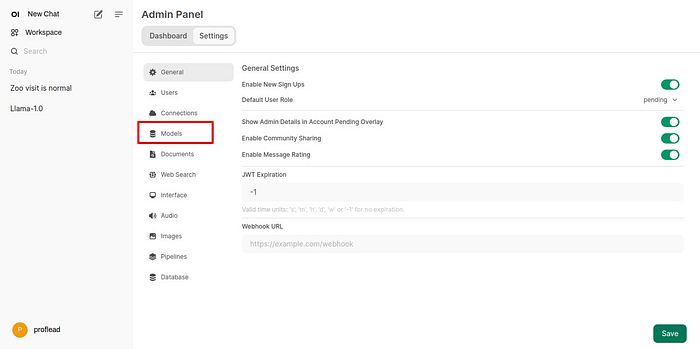
Models
4. In the input field, write the name of the model you would like to pull and click on the “download” icon.
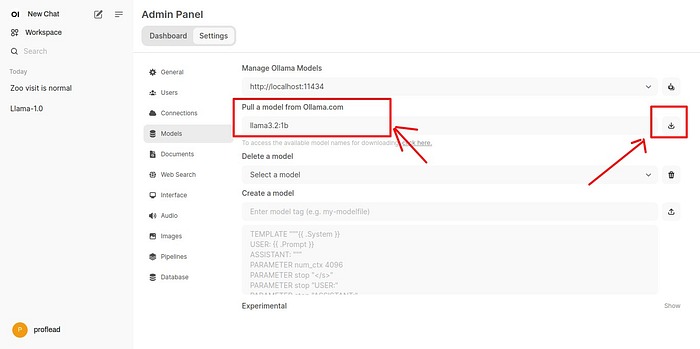
Pull the models
All the names you can find on https://ollama.com/library/llama3.2
This should fix the issue.
Conclusion
Running Llama 3.2 locally provides significant advantages regarding privacy and control over AI applications. But to have a smooth experience, you would need a powerful computer. :)
If you like this tutorial, please follow me on YouTube, join my Telegram, or support me on Patreon.
Thanks! :)